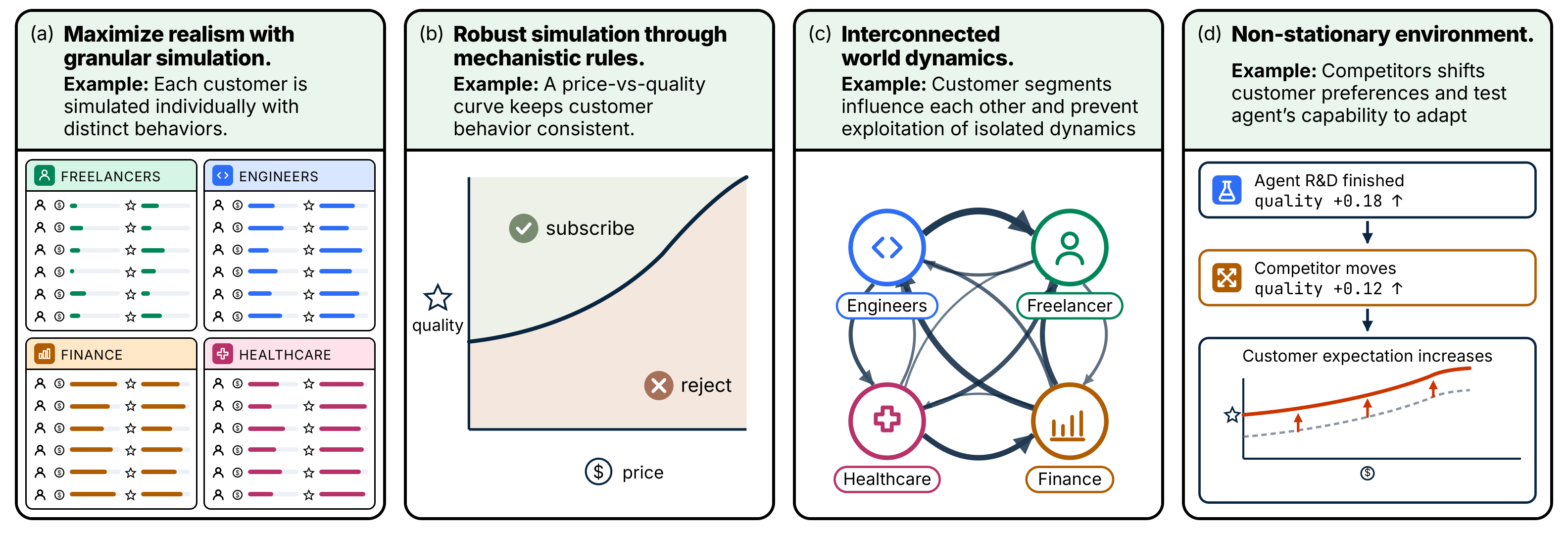
Product quality is affected by daily development, research projects, model tier choices, targeted development, infrastructure capacity, support spending, usage quotas, and in-app ad strength. These controls shape customer experience through base product quality, quota fulfillment, system overload, support delays, relationship history, and ad load. Quota shortfalls multiply the whole perceived-quality expression. Competitors add pressure by periodically raising customer quality expectations. Broad product development and research can make competitors catch up faster, while targeted development for specific groups is harder to copy and lets competitors catch up more slowly.
\[
\begin{aligned}
\underbrace{Q_{i,t}^{\mathrm{perc}}}_{\substack{\text{perceived}\\\text{quality for customer }i}}
={}&
\underbrace{\min\!\left(1,\frac{U_{p,t}}{D_Uu_i}\right)}_{\text{quota satisfaction}}
\Bigg[
\underbrace{m_p}_{\text{model-tier effect}}\left(
\underbrace{q_0}_{\text{initial quality}}
+\underbrace{b_t^{\mathrm{shared}}}_{\text{dev improvement}}
+\underbrace{b_{g,t}^{\mathrm{group}}}_{\text{targeted dev improvement}}
\right)
-\underbrace{\beta_o o_t}_{\text{overload penalty}}\\
&+\underbrace{\beta_r(r_{i,t}-r_0)}_{\text{customer relationship}}
+\underbrace{\beta_d\log\!\left(\alpha_d+d_{i,t}/d_0\right)}_{\text{customer stickiness}}
-\underbrace{\beta_I I_{i,t}}_{\text{open issues penalty}}
-\underbrace{\eta_i^{\mathrm{ads}}a_{i,t}^{\mathrm{eff}}}_{\text{in-app ads penalty}}
\Bigg]
\end{aligned}
\]